
Ch2主要是对机器学习中的回归问题进行建模,以及对损失函数相关问题进行了数学上的推导分析。本篇笔记除了对以上进行归纳外,也用Matlab实现了线性回归问题的解决。
1. 回归问题解决逻辑

2. 梯度下降法
针对一组训练集,我们可以提出多个假设函数(Hypothesis)。一旦我们确定了假设函数的形式,其参数需要通过训练得到。如何得知参数是否合适,这就需要用损失函数(Cost Function)来验证我们构造的函数是否优良,
进而又对参数进行更新,形成闭环。
损失函数J(θ)一般有多个自变量θ_i,其图形是一个高维图。我们一般不会以画图寻找最小值,而需要通过优化算法求取。
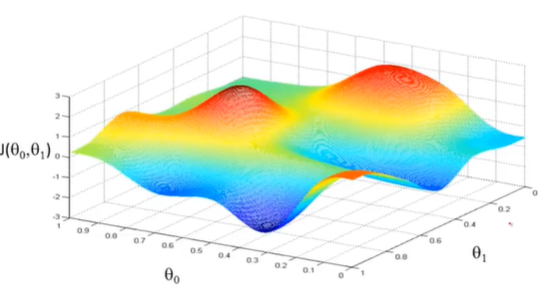
微积分中,一般通过对多元函数的自变量求偏导数,以向量形式呈现的各自变量偏导数即为梯度向量。多元函数在某一点的梯度向量即为此函数在该点增速最快(相同步长,函数值增加最大)的地方。由此可知,沿着梯度向量的方向,函数增加越快,更容易找到最大值。反之,逆着梯度向量的方向,则函数减小最快,更容易找到最小值。梯度下降法Gradient descent)便秉承了这一思想。

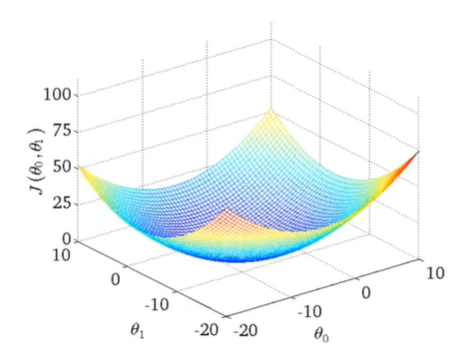
一个多元函数,可能有多个局部极小值,而梯度下降法有可能陷入局部最优解的问题。特别地,如果函数是一个凸函数(Convex Function)时,因只有一个局部最小值即全局最小值,梯度下降法总是能够收敛到全局最优解。
2.1 梯度下降法的相关概念
假设函数:h_θ (x),拟合样本及其标签使用的函数。
损失函数:J(θ),评估假设函数拟合的程度。
学习率:α,每次迭代过程,每一步沿梯度负方向前进的长度。
- 学习率太小,梯度下降法到达最小值时间较长(收敛速度慢)。
- 学习率较大,梯度下降法可能无法收敛甚至发散。
- 接近局部最小值时,移动的幅度越来越小.
2.2 梯度下降法的步骤
Step1:初始化损失函数各参数值,求取损失函数当前所处位置的梯度
$$∂/(∂θ_i ) J(θ_0,θ_1,…,θ_n ),i=0,1,…,n$$
Step2:更新损失函数的参数
$$θ_i:=θ_i-α ∂/(∂θ_i ) J(θ_0,θ_1,…,θ_n ),i=0,1,…,n$$
Step3:重复Step2直到某次更新是所有参数变化值均小于ε,结束程序
3. 针对线性回归问题的编程实现(Matlab)
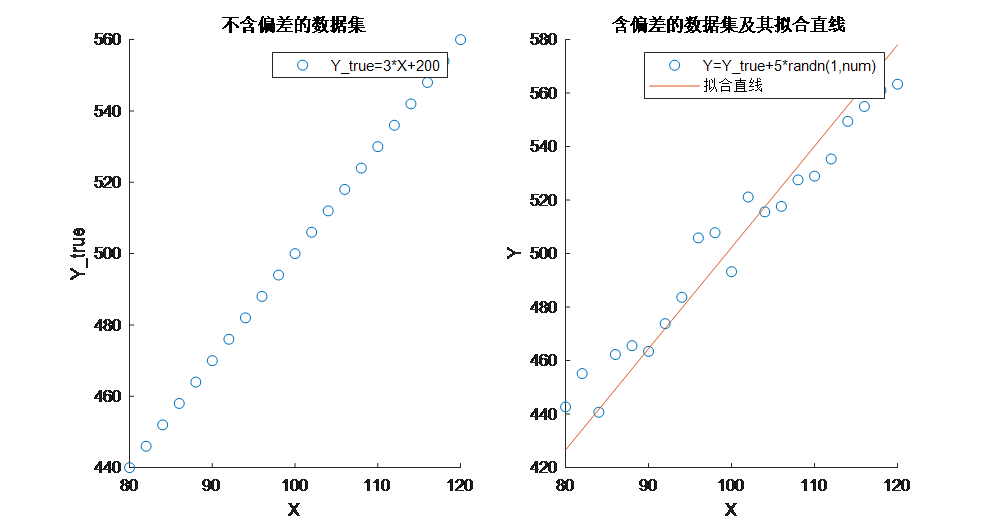
接下来我们通过Matlab对一个简单的线性回归问题做一个解决。代码思路如下:

最终可视化结果如下:
编程实现 :
1 | %% Coded by MinYi Wu |
#参考
- 吴恩达-机器学习-ch2