
Support Vector Machine
优化目标
因为SVM也是解决分类问题的机器学习算法,所以我们可以从logistic函数出发,推导SVM的假设函数形式。
Logistic函数的单个样本损失:
$$
-(y \ log \ h_\theta(x)+(1-y)\ log(1-h_\theta(x)))
$$
其中$h_\theta(x)=\frac{1}{1+e^(-\theta^Tx)}$,注意其中$h_\theta(x)<1$,故-log为正。
分别画出当y=1/0时的(1)式图像,可以进行函数替换。下图中红色虚线为logistic损失函数图像,蓝色实线时hinge loss函数图像。


因此可以考虑将$h_\theta(x)$的解析式进行转化,简化(1)式:
$$
y \ cost_1(-\theta x)+(1-y) \ cost_0(\theta x)
$$
故我们的优化目标从
$$
\min_\theta \frac{1}{m} \ \sum_{i=1}^m[ y^{(i)}(1-log \ h_\theta(x^{(i)}))+ (1-y^{(i)})\ log(1-h_\theta(x)) ]+ \frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2
$$
变为
$$
\min_\theta \frac{1}{m} \ \sum_{i=1}^m[ y^{(i)}cost_1(-\theta x)+ (1-y^{(i)})\ cost_0(\theta x) ]+ \frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2
$$
(4)式的形式为$A+\lambda B$,可以简化为$CA+B$,其中$C=1/\lambda$。
所以4)式又可以简化为
$$
\min_\theta C \ \sum_{i=1}^m[ y^{(i)}cost_1(-\theta x)+ (1-y^{(i)})\ cost_0(\theta x) ]+ \frac{1}{2}\sum_{j=1}^n\theta_j^2
$$
直观上对最大间隔的理解
1. 更严格的分类标准
logistic回归对分类样本只需要假设函数$h_\theta(x)$中的$\theta x$>=0或<0即可,但SVM有更强的分类标准,由其损失函数hinge loss的图像可知:
- 当y=1时,我们想要$\theta x\geq 1$
- 当y=0时,我们想要$\theta x\leq -1$
2.鲁棒or精细
从(5)式可以看出,当C超级大时,SVM分类器关注于尽可能不分错以使损失函数最小化,而当决策边界离正负样本同样远时,损失函数才会有最小值。但也可以看到,当样本中出现个别噪声点时,此时SVM不鲁棒。
大间隔分类器的数学原理
当C超级大时,优化目标(5)式的前半部分必须无限趋于0,此时故我们只需要优化后半部分。
$$
\min_\theta \frac{1}{2}\sum_{j=1}^n \theta_j^2
\
s.t.\theta^Tx^{(i)}\geq1 \quad if\ y^{(i)}=1\
\quad \quad \theta^Tx^{(i)}\leq-1 \quad if\ y^{(i)}=0
$$
定义假设函数中的参数$\theta$的分量$\theta_0=0$,此时问题得到简化,决策边界过原点。由于决策边界的方程为$\theta x=0$,所以$\theta$一定与决策边界垂直。此时(6)式可化为
$$
\min_\theta \frac{1}{2}\sum_{j=1}^n \theta_j^2
\
s.t.p^{(i)}||\theta||\geq1 \quad if\ y^{(i)}=1\
\quad \quad p^{(i)}||\theta||\leq-1 \quad if\ y^{(i)}=0
$$
式中,$p^{(i)}$是$x^{(i)}$在向量$\theta$上的投影。
当$\theta_0!=0$时,认可通过决策边界和样本点的欧式变换(即平移、旋转),完成决策边界的平移。
Kernel
非线性假设
若是非线性的决策边界,则假设函数需要变得更复杂,即需要更复杂的组合特征。

为了获得上图所示的判定边界,我们的模型可能是$\theta_0+\theta_1x_1+\theta_2x_1x_3+…$的形式。如何得到这些组合特征呢?一种方法是利用已知数据来预测未知数据,即给定一个测试样本$x_{test}$,通过其与地标样本点$f_1,f_2,…$的相似度来计算$x_{test}$的预测值,相似度的度量我们使用相似度函数(Kernel)进行计算。
首先我们知道两个样本点的特征距离越近,则相似度越大,越远则相似度越小。故我们可以通过计算两个样本点之间特征距离和来计算相似度。取相似度函数为
$$
f_1=similarity(x,l^{(1)})=exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2})
$$
从上式可以看出:
- 若$x≈l^{(1)}$,则$f_1≈1 $
- 若$x \ far \ away \ from \ l^{(1)}$,则$f_1≈0$
例如,取$l^{(1)}=[3,5]^T$,选取不同的$\sigma^2$值,f1的图像如下所示。

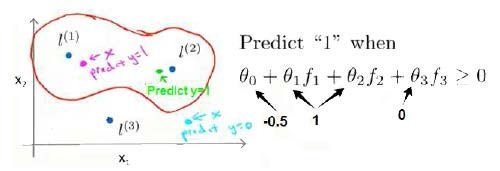
例子:这里我们取3个地标样本点,在给定$\theta_0,…,\theta_3,l_1,…,l_3$后,当样本处于洋红色的点位置处,因为其离$l^{(1)}$更近,但是离$l^{(2)}$和$l^{(3)}$较远,因此接$f_1$近1,而$f_2$,$f_3$接近0。因此$h_\theta(x)=\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3>0$,预测$y=1$。同理可以求出,对于离较近的绿色点,也预测$y=1$,但是对于蓝绿色的点,因为其离三个地标都较远,预测$y=0$。
引入了Kernel的SVM,目标函数变为
$$
\min_\theta C \ \sum_{i=1}^m[ y^{(i)}cost_1(-\theta^T f^{(i)})+ (1-y^{(i)})\ cost_0(\theta^T f^{(i)}) ]+ \frac{1}{2}\sum_{j=1}^{n=m}\theta_j^2
$$
此时对最后一项正则项进行微调整,即$\sum_{j=1}^{n=m}\theta_j^2=\theta^T\theta\approx\theta^TM\theta$,其中M为根据选择的和函数不同而不同的一个矩阵,可以简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用 来简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
如何选择$l_i$
如果训练集给定样本${(x^{(1)},y^{(1)}),…,(x^{(m)},y^{(m)})}$,则将$l^{(i)}=x^{(i)},i=1,…m$,对后面给定的测试样本,计算
$$
f_1=similarity(x,l^{(1)})\
f_2=similarity(x,l^{(2)})\
\vdots
$$
对训练集中每个样本${(x^{(i)},y^{(i)})}$,有$f_i^{(i)}=1$。
如何选择$C$
$C=1/\lambda $
大的C,$\lambda$小,可能会过拟合,低偏差,高方差
小的C,$\lambda$大,可能会欠拟合,高偏差,低方差
如何选择$\sigma^2$
- $\sigma^2$过大,特征$f_i$分布越广,高偏差,低方差
- $\sigma^2$过小,特征$f_i$分布越密,低偏差,高方差
使用SVM
软件库:liblinear,libsvm
SVM求解所需:
- C
- Kernel:选择的Kernel函数需要满足Mercer’s Theorem,优化函数才能正常运行而不会发散
- Linear Kernel
- Gaussian Kernel:选择$sigma^2,l_i $
- Polynomial Kernel
- String Kernel
- chi-square Kernel
- histogram Kernel
- intersection Kernel
多分类问题
对分成K类的样本,训练K个SVM,一个SVM将一类样本与其他K-1类样本区分开,得到参数$\theta^{(i)},…,\theta^{(K)}$,选择最大的$(\theta^{(i)})^Tx$为测试样本$x$的类(i)。
Logistic Regression vs. SVM
n:特征数量
m:训练集样本数理
- 当n相对m过大,使用LR,或者SVM with Linear Kernel
- 当n小,m中等,使用SVM with Gauss Kernel
- 当n小,m大,加入更多的特征后,使用LR,或SVM without Kernel
- 神经网络在大多数情况能够效果很好,但是训练费力。