
孪生神经网络(Siamese network)
“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
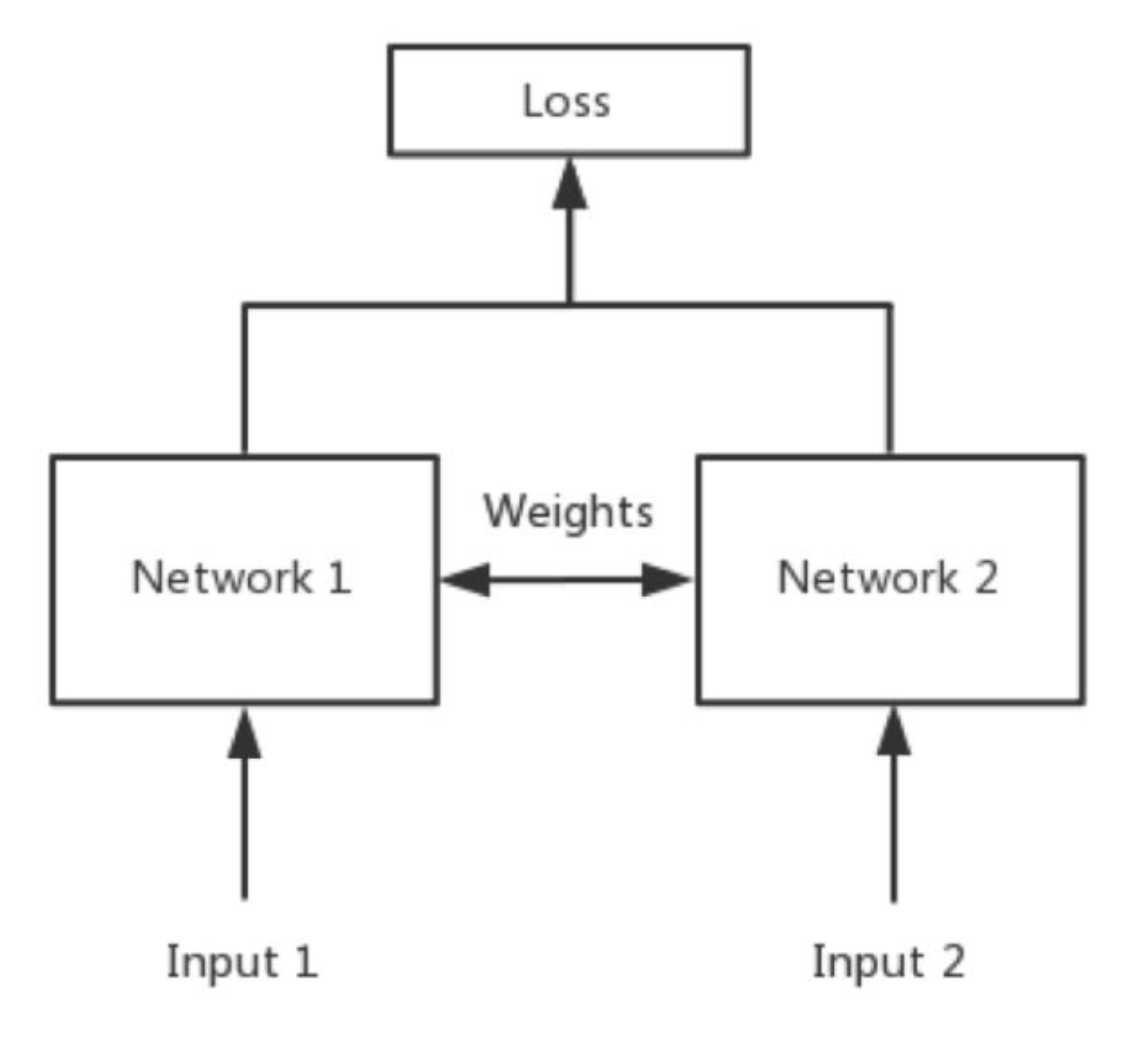
在代码实现的时候,两个network甚至可以是同一个网络,不用实现另外一个,因为权值都一样。对于siamese network,两边可以是lstm或者cnn。
孪生神经网络(Pseudo-Siamese network)
两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
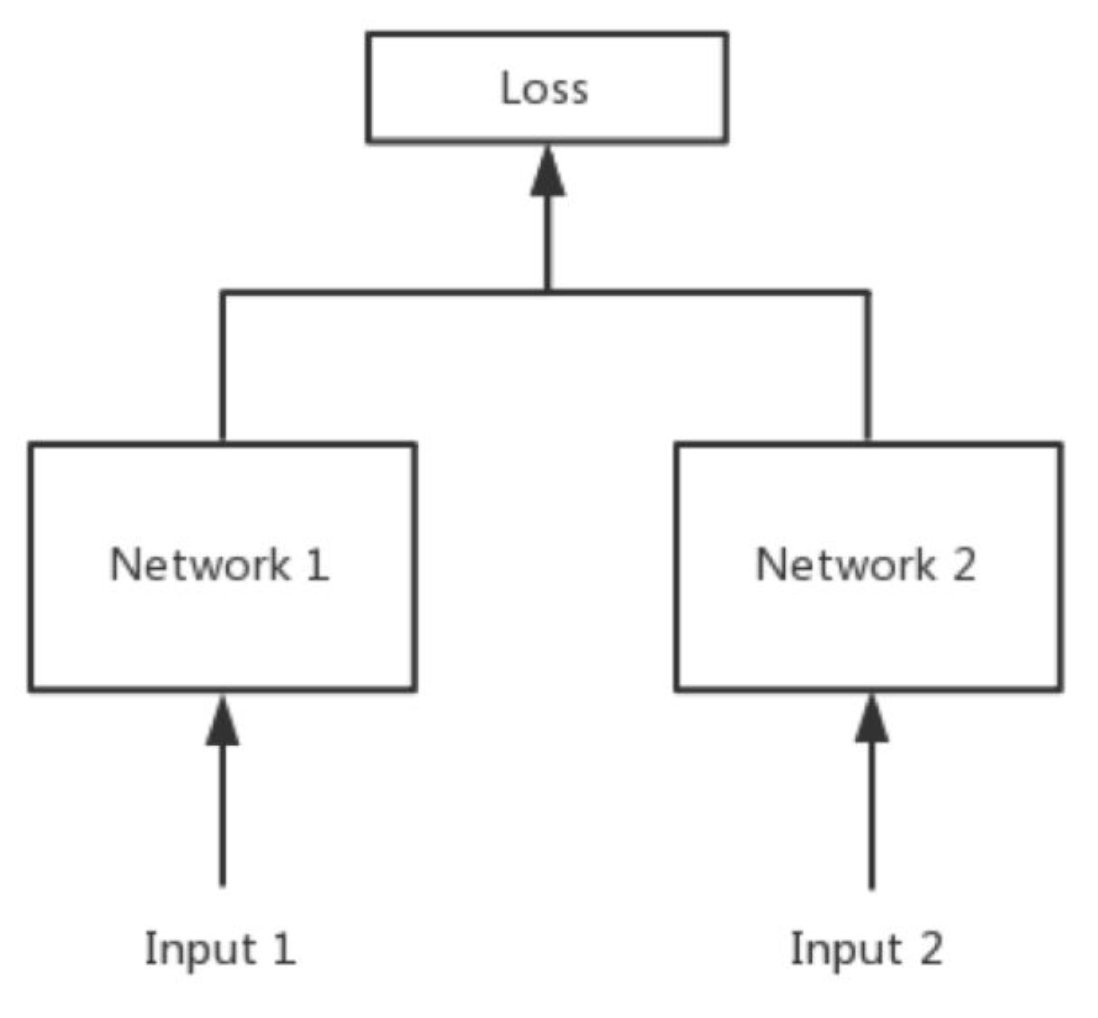
两者区别
孪生神经网络用于处理两个输入”比较类似”的情况。伪孪生神经网络适用于处理两个输入”有一定差别”的情况。
孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。也就是说,要根据具体的应用,判断应该使用哪一种结构,哪一种Loss。
损失函数的选择
siamese network的初衷是计算两个输入的相似度。左右两个神经网络分别将输入转换成一个”向量”,在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大。其他的距离度量没有太多经验,这里简单说一下cosine和exp在NLP中的区别。
根据实验分析,cosine更适用于词汇级别的语义相似度度量,而exp更适用于句子级别、段落级别的文本相似性度量。其中的原因可能是cosine仅仅计算两个向量的夹角,exp还能够保存两个向量的长度信息,而句子蕴含更多的信息。