
Ch7本章讲的是关于模型训练过程会出现的欠拟合、过拟合的问题,以及它们的解决思路。重点介绍了过拟合问题的正则化方法,并对回归和分类问题的损失函数进行了重定义。
$$$
$
$$$
$
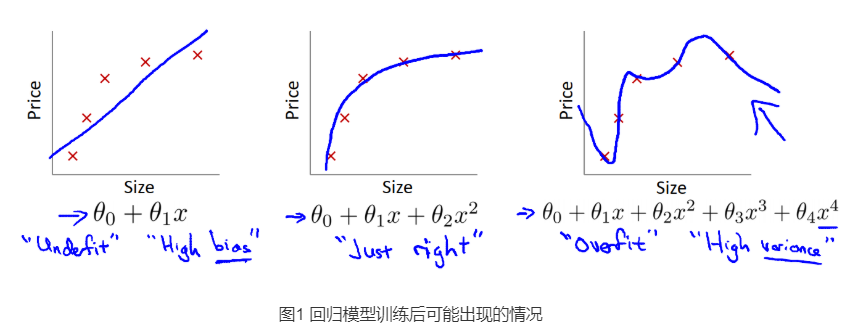
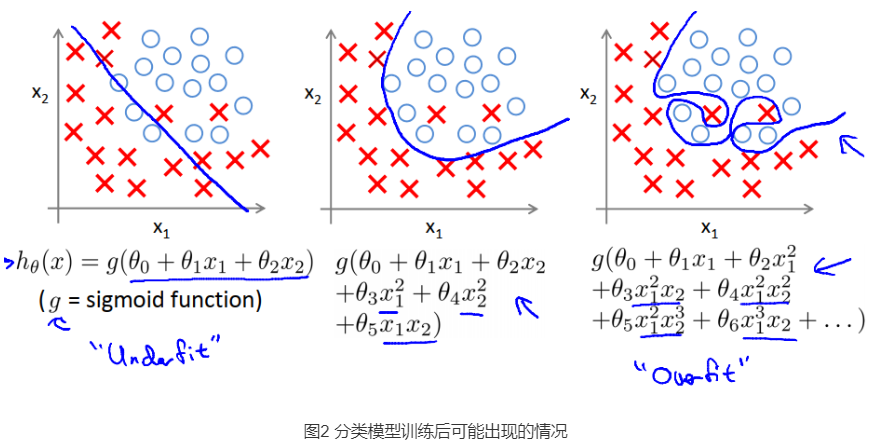
两种模型在训练过程均可能出现三种情况:欠拟合->良好->过拟合。
过拟合是因为对训练集的过度学习而造成的,模型泛化到测试集的效果远差于训练集。欠拟合可通过训练/增加样本量来解决。
过拟合:
减少特征变量
- 手工选取
- 模型选择算法
正则化
- 保留参数,降其权重
- 各参数均有用
正则化即对参数加上惩罚项,以使得模型更简单。
无法得知对哪些参数进行惩罚,故对所有的参数进行惩罚。
新的损失函数如下:
$$J’(\theta)=J(\theta)+\frac{1}{2m}\lambda\sum_{j=1}^{n}\theta_j^2 \tag{7-1}$$
其中$J(\theta)$为初始损失函数,目的是让拟合效果更好。
- 回归模型的$J(\theta)$
$$J(\theta)=\frac{1}{2m}\sum_{i=1}^{n}(h_\theta(x^{(i)})-y^{(i)})^2 \tag{4-2}$$ - 分类模型的$J(\theta)$
$$J(\theta)=\frac{1}{m}\sum_{i-1}^{m}[-y^{(i)}log(h_\theta(x^{(i)}))-(1-y^{(i)})log(1-h_\theta(x^{(i)}))] \tag{6-2}$$ - 两个模型的正则化最终损失函数均为$J’(\theta)=J(\theta)+\frac{1}{2m}\lambda\sum_{j=1}^{n}\theta_j^2$
而$\lambda\sum_{j=1}^{n}\theta_j^2$为了使参数更简单。其中$\lambda$为正则化系数。
- 若$\lambda$过大,则模型可能会欠拟合
- 若$\lambda$过小,则惩罚效果差
对线性回归模型进行正则化
更新后的梯度下降法:
$$\theta_j:=\theta_j(1-\alpha\frac{\lambda_j}{m})-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \qquad j=0, \cdots ,n \tag{7-2}$$
其中$
\lambda_j=
\begin{cases}
0& \text{j=0}\
1& \text{j=1,\dots,n}
\end{cases}$,$h_\theta(x)=\theta^Tx$。
更新后的正规方程法:
因较少的样本,导致特征数量大于样本数量,则矩阵 $X^TX$ 将是不可逆矩阵,或称其为退化(degenerate)、奇异(singluar)矩阵。那么我们就没有办法使用正规方程来求出θ 。
$$X=\begin{bmatrix}
(x^{(1)})^T\
\vdots\
(x^{(m)})^T
\end{bmatrix}\in R^{m \times n},
y=\begin{bmatrix}
(y^{(1)})^T\
\vdots\
(y^{(m)})^T
\end{bmatrix} \in R^{m}
$$
$X \in R^{m\times (n+1)}$,其中$m\leq n$
- 若m<n,$X^TX$ 一定不可逆
- 若m=n,$X^TX$ 可能不可逆
对$X^TX$加上惩罚项,得到的新矩阵一定可逆,于是正规方程法永远可以成立。
欲$\min \limits_\theta J’(\theta)$,需要$\frac{\partial}{\partial{\theta_j}}J’(\theta)\overset{\text{set}}{=}0$,得到
$$\theta=(X^TX+\lambda
\begin{bmatrix}
0\
&1\
& &1\
& & & \ddots\
& & & &1
\end{bmatrix}
)^{-1}X^Ty \tag{7-3}$$
$\begin{bmatrix}
0\
&1\
& &1\
& & & \ddots\
& & & &1
\end{bmatrix}
$中对角线上第一个元素为0是对常数系数$\theta_0$不做惩戒,X的第一维度也是$\theta_0$。
对Logistic回归模型进行正则化
更新后的梯度下降法:
$$\theta_j:=\theta_j(1-\alpha\frac{\lambda_j}{m})-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \qquad j=0, \cdots ,n \tag{7-2}$$
其中$
\lambda_j=
\begin{cases}
0& \text{j=0}\
1& \text{j=1,\dots,n}
\end{cases}$,$h_\theta(x)=\frac{1}{1+e^{-\theta^Tx}}$。
拓展:Lasso回归&Ridge回归
Lasso regression 和 Ridge regression
Lasso 回归和Ridge回归都是在标准线性回归的基础上修改代价函数$J(\theta)$,其它地方不变。
Lasso 的全称为 least absolute shrinkage and selection operator,又译最小绝对值收敛和选择算子、套索算法。其代价函数为
$$J’(\theta)=J(\theta)+\lambda||\theta||_1 \tag{7-4}$$
岭回归的代价函数为
$$J’(\theta)=J(\theta)+\lambda||\theta||_2^2 \tag{7-5}$$
Lasso回归和Ridge回归的同和异:
相同:
- 都可以用来解决标准线性回归的过拟合问题。
不同:
- Lasso 可以用来做 feature selection,而 Ridge 不行。或者说,Lasso 更容易使得部分参数权重变为0,而 Ridge 更容易使得部分参数权重接近0。
- 从贝叶斯角度看,Lasso(L1 正则)等价于参数 \theta 的先验概率分布满足拉普拉斯分布,而 Ridge(L2 正则)等价于参数 \theta 的先验概率分布满足高斯分布。具体参考博客从贝叶斯角度深入理解正则化 – Zxdon 。
L1 / L2 正则化项,可让各参数的值大小对损失函数影响均很大,最后构造一个所有参数都比较小的模型。
一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。
设想一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什幺影响,一种流行的说法是『抗扰动能力强』。
为何Lasso较Ridge更容易使部分参数权重变为零
Lasso 和 Ridge regression 的目标都是 $\min \limits_{\theta}J’$,式(7-4)和(7-5)都是拉格朗日形式(\thetaith KKT条件),其中$\lambda$为 KKT 乘子,我们也可以将 $\min \limits_{\theta}J’$ 写成如下形式:
$$\min \limits_{\theta}J \quad
s.t. \begin{cases}
||\theta||_1 \leq t& \text{Lasso regression}\
||\theta||_2^2 \leq t& \text{Ridge regression}
\end{cases}
$$
上式的限制条件可以理解为,在$\theta$限制的取值范围内,找一个点$\hat{\theta}$使得均方差 $J(\theta)$ 最小。 $t$ 可以理解为正则化的力度,$t$ 越小,就意味着式(7-4)和(7-5)中 $\lambda$ 越大,正则化的力度越大 。
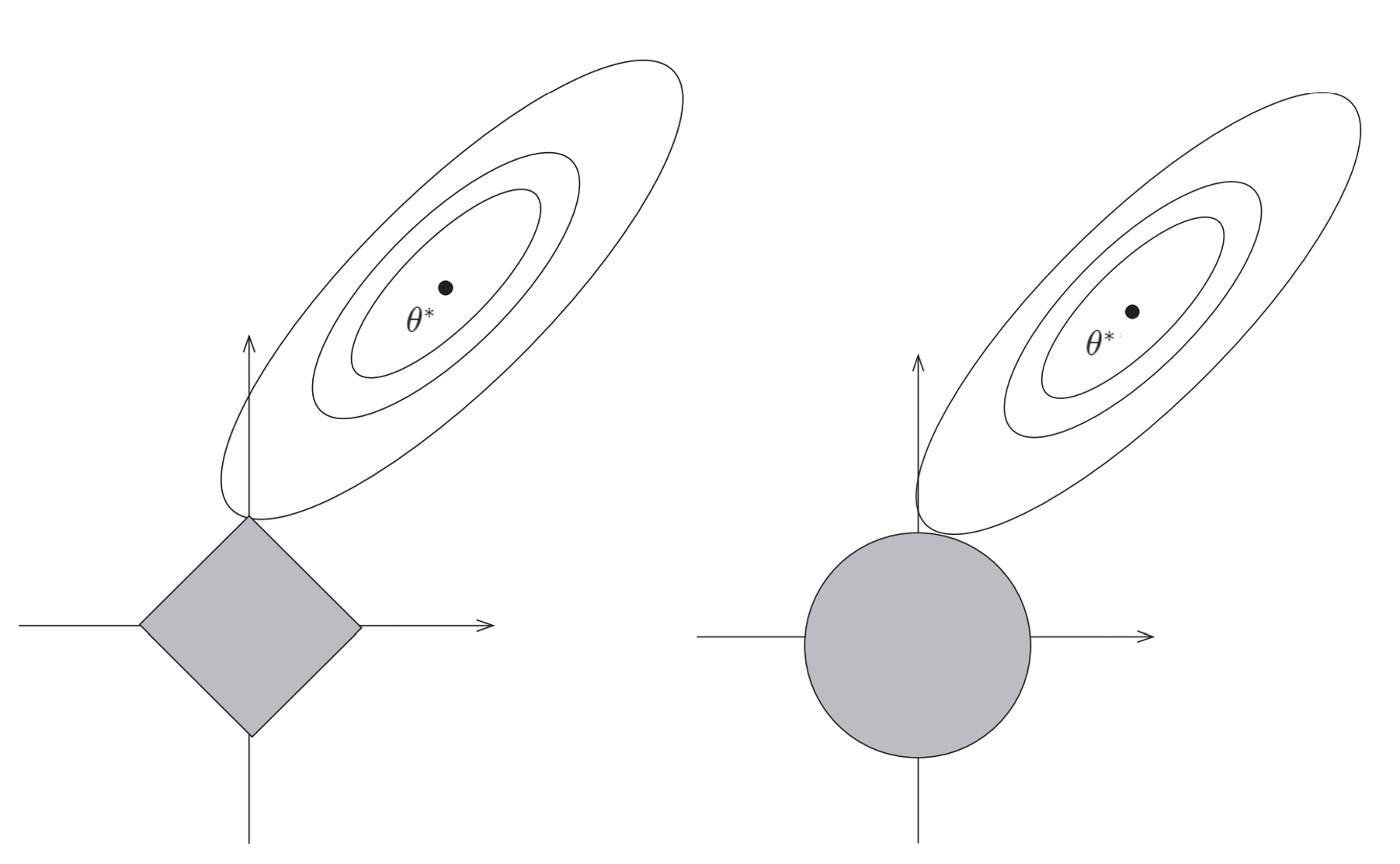
以 $x \in R^2$ 为例,损失函数$J(\theta)$的两个参数为$\theta_0、\theta_1$
- L1正则项的约束即为$|\theta_0|+|\theta_1| \leq t$,是对 $\theta$ 的中心点在原点的方形限制;
- L2正则项的约束为$\theta_0^2+\theta_1^2 \leq t$,是对 $\theta$ 的中心点在原点的圆形限制。
- 通过调整 $t$ 的值,能够调整这两个区域的大小。
因为 Lasso 对 $\theta$ 的限制空间是有棱角的,因此 $arg \min \limits_\theta J$ 的解更容易切在 $\theta$ 的某一个维为 0 的点。
等值线和方形区域的切点更有可能在坐标轴上,而等值线和圆形区域的切点在坐标轴上的概率很小。 Lasso(L1 正则化)更容易使得部分权重取 0,使权重变稀疏;而 Ridge(L2 正则化)只能使权重接近 0,很少等于 0。
权重为 0 的 feature 对模型没有贡献,故 Lasso 可以做 feature selection,Ridge 删去趋于 0 的 feature会对模型有损伤。
$$$
$
图3中的xy轴表示 $\theta$ 的参数维,一圈圈的椭圆表示函数 $J(\theta)$ 的等值线,$\theta^∗$ 表示损失 $J$ 的全局最优值的参数,离 $\theta^*$ 越远的椭圆 $J(\theta)$ 的值越大。
使用 Gradient descent,会使 $\theta$ 向着 $\theta^∗$ 的位置走。如果没有 L1 或者 L2 正则化约束,$\theta^∗$ 是可以取得的。但是,由于有了约束,$\theta$ 的取值只能限制在图3所示的灰色方形和圆形区域。
等值线从外围到内围第一次和 $\theta$ 的取值范围相切的点,即是 Lasso 和 Ridge 回归想要找的权重 $\hat{\theta}$。
参考
latex语法参考:
内容参考:
- 吴恩达-机器学习ch7
- Lasso regression 和 Ridge regression