
Ch6主要是对机器学习中的分类问题进行建模。
“逻辑斯提克回归”的名字来源是源于Logistic函数,因为有用到线性回归的函数,所以合称为“Logistic Regression”。首先对二分类问题进行讨论,定义了新的损失函数,并对该损失函数的来源(极大似然估计)以及损失函数的梯度下降法进行了推导。
多分类问题是在二分类问题上的进一步延伸。
分类问题
例子:
- 邮件分类
- 交易是否属于欺诈
- 良恶肿瘤
分类问题的分类:
- 二分类:$y=0 \ or \ 1$
- $h_\theta(x)$可以是>1 or <0
- 使用线性回归效果不好,容易受离群值影响
- logistic regression:$0\leq h_\theta(x) \leq1$,普遍应用的分类算法
- 多分类
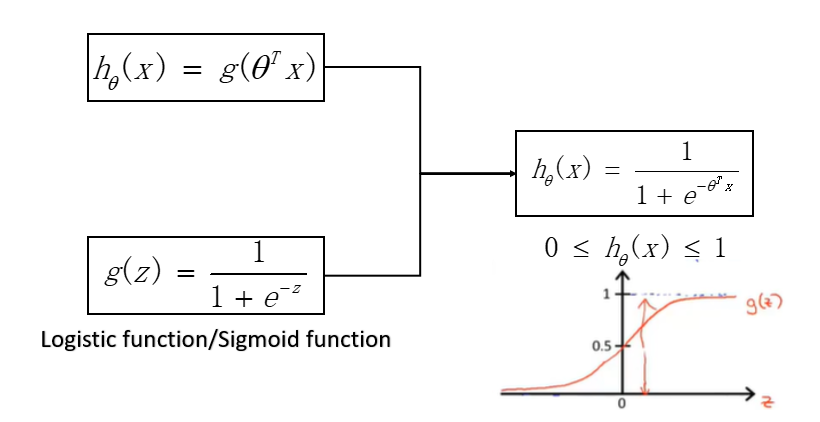
Logistic Regression
$$$
$
可以看出logistic regression满足一下两个条件:
$$h_θ (x)=P(y=1|x;θ)$$
$$P(y=1│x;θ)+P(y=0│x;θ)=1$$
$h_θ (x)$表示在假设函数的参数下,给定特征x代表y=1的概率。
- 当$h_θ (x)≥0.5<=>θ^T x≥0$,认定$y=1$;
- 当$h_θ (x)<0.5<=>θ^T x<0$,认定$y=0$。
$1-h_θ (x)$表示在假设函数的参数下,给定特征x代表y=0的概率。
决策边界 Decision Bounding
$h_\theta(x)=0.5$的直线。是假设函数的固有属性,只要给定了假设函数的参数,则决策边界唯一确定。

$$$
$
当界限越来越难分,可以通过构造复杂的特征得到更复杂的决策边界。
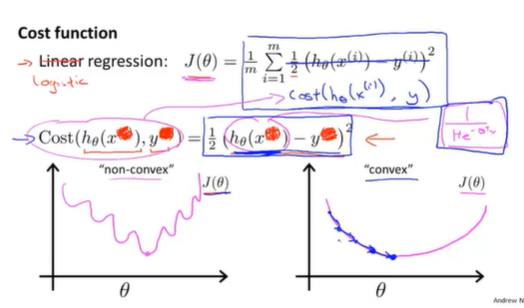
损失函数
损失函数的作用:
寻找假设函数的最优参数$\theta$。
$$$
$
若使用均方差作为损失函数,有局部极小值,难以达到全局最小值。所以需要重新定义损失函数,使之成为凸函数可以使用梯度下降法。
构想单个预测的损失函数:
$$
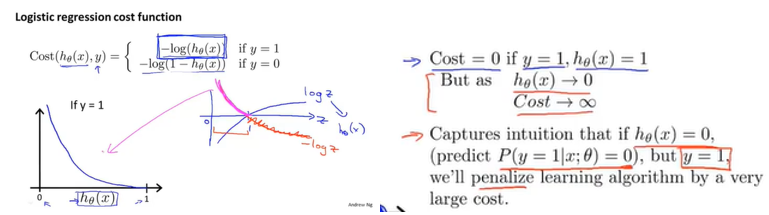
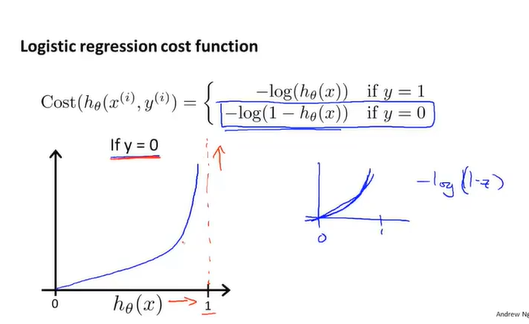
Cost(h_\theta(x),y)=-ylog(h_\theta(x))-(1-y)log(1-h_\theta(x)) \tag{6-1}
$$
$$$
$
当y=1,若$h_\theta(x)$=1时,单个预测的损失函数值为0;而$h_\theta(x)$趋向于0时,单个预测的损失函数值无穷大。符合单个预测的损失函数的定义。
$$$
$
当y=0,同理可知单个预测的损失函数也符合定义。
且单个预测的的损失函数是一个凸函数,可以使用梯度下降法进行迭代。
得到整体的损失函数:
$$\begin{aligned}
J(\theta)&=\frac{1}{m}\sum_{i-1}^{m}Cost(h_\theta(x^{(i)}),y^{(i)})\ \tag{6-2}
&=\frac{1}{m}\sum_{i-1}^{m}[-y^{(i)}log(h_\theta(x^{(i)}))-(1-y^{(i)})log(1-h_\theta(x^{(i)}))]
\end{aligned}
$$
为啥选上式作为Logistic Regression的损失函数?
上式是Logistic Regression问题的对数似然函数,以此可快速为模型寻找参数,而且这个损失函数是凸的。
极大似然法估计
Cost函数和J函数均是由极大似然法推导得到。过程如下(参考自Logistic Regression损失函数理解):
$$\begin{aligned}
P(y=1|x;\theta)&=h_\theta(x)\
P(y=0|x;\theta)&=1-h_\theta(x) \tag{6-3}
\end{aligned}
$$
对(6-3)进行合并,可得到
$$
P(y|x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y} \tag{6-4}
$$
取似然函数为
$$L(\theta)=\prod_{i=1}^{m}P(y^{(i)}|x^{(i)};\theta)=\prod_{i=1}^{m}(h_\theta(x^{(i)}))^{y^{(i)} }(1-h_\theta(x^{(i)}))^{1-y^{(i)} } \tag{6-5} $$
对数似然函数为
$$l(\theta)=logL(\theta)=\sum_{i=1}^{m}[{y^{(i)} }log{(h_\theta(x^{(i)}))}+{(1-y^{(i)})}log(1-h_\theta(x^{(i)}))] \tag{6-6} $$
最大似然估计是取$\theta$使得$l(\theta)$取得最大值。这里令损失函数为$J(\theta)=-\frac{1}{m}l(\theta)$,取其最小值,即取似然函数的最大值。
求似然函数最大值,就是求出损失函数的最小值,由此得到的是假设函数的最优参数$\theta$。这就是Logistic Regression损失函数的数学推导。
梯度下降法
这里对$J(\theta)$的迭代公式为:
与多元线性回归梯度下降迭代公式相同
$$\theta_j:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \tag{6-7}$$
$$j=0, \cdots ,n$$
推导过程:参考Logistic Regression代价函数导数求解过程
$$
\begin{aligned}
J(\theta)
&=-\frac{1}{m}\sum_{i=1}^{m}[{y^{(i)} }log{(h_\theta(x^{(i)}))}+{(1-y^{(i)})}log(1-h_\theta(x^{(i)}))]\
&=-\frac{1}{m}\sum_{i=1}^{m}[-{y^{(i)} }log{(1+e^{-\theta x^{(i)} })}+(1-y^{(i)})(-\theta x^{(i)}-log{(1+e^{-\theta x^{(i)} })})]\
&=-\frac{1}{m}\sum_{i=1}^{m}[{y^{(i)} }\theta x^{(i)}-\theta x^{(i)}-log{(1+e^{-\theta x^{(i)} })}]\
&=-\frac{1}{m}\sum_{i=1}^{m}[{y^{(i)} }\theta x^{(i)}-log{(1+e^{\theta x^{(i)} })}]\
\end{aligned}$$
由
$$
\left {
\begin{aligned}
&\frac{\partial{} }{\partial{\theta_j} }{ {y^{(i)}\theta x^{(i)} }}=y^{(i)}x_j^{(i)}\
&\frac{\partial{} }{\partial{\theta_j} }{log{(1+e^{\theta x^{(i)} })} }=\frac{x_j^{(i)}e^{\theta x^{(i)} }}{1+e^{\theta x^{(i)} }}=x_j^{(i)}h_\theta(x^{(i)})
\end{aligned}
\right .
$$
得到
$$
\frac{\partial{J(\theta)} }{\partial{\theta_j} }=-\frac{1}{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}=\frac{1}{m}(y^{(i)}-h_\theta(x^{(i)}))x_j^{(i)}
$$
(6-7)梯度下降法成立。特征归一化能使Logistic Regression收敛加快。
可使用正规方程法一次得到所有的$\theta$值。
优化算法
- 梯度下降法
- 共轭梯度法
- BFGS
- L-BFGS
相比于梯度下降法,其他三个优化算法:
- 优点:
- 不需要手动设置学习率$\alpha$
- 收敛速度比其更快
- 缺点:
- 算法更为复杂
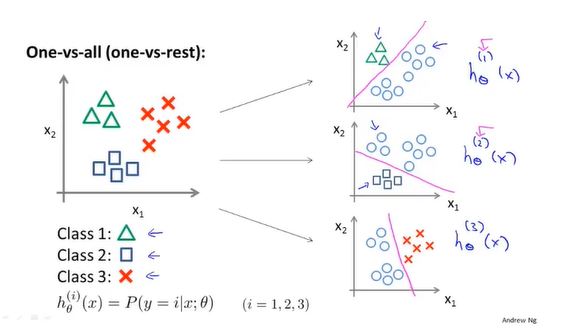
多分类问题
每个类别i训练一个Logistic Regression分类器$h_\theta^{(i)}(x)$。
对每个输入样本x,取各分类器预测概率值最高的为其类别:
$$\max \limits_i h_\theta^{(i)}(x)$$
$$$
$