
Ch4主要是对机器学习中的多元回归问题进行建模,这里的多元指的是多个特征。其中特征可以由多个单特征构成,也可由单特征的指数/对数/次方…等运算项构成。
假设函数取线性公式;损失函数仍然采用了均方差公式。除了用梯度下降法进行参数更新外,还提出了正规方程法,可以一步到位计算出参数,但也有其局限所在。
针对数值特征,进一步提出能加快梯度下降法迭代速度的归一化概念。
多元线性回归
$n$:特征数量
$x^{(i)}$:第i个输入
${x}_j^{(i)}$:第i个输入的第j个特征
$y^{(i)}$:第i个输入的标签
参数:$\theta$
假设函数:
$$
h_\theta(x)=
{\left[
\begin{matrix} \theta_{0} & \cdots & \theta_{n} \end{matrix}
\right ]}
{\left[
\begin{matrix} x_{0} \ \cdots \ x_{n} \end{matrix}
\right ]}=\theta^Tx \tag{4-1}
$$
代价函数:
$$J(\theta)=\frac{1}{2m}\sum_{i=1}^{n}(h_\theta(x^{(i)})-y^{(i)})^2 \tag{4-2}$$
梯度下降法:
$$\theta_j:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \tag{4-3}$$
$$j=0, \cdots ,n$$
单特征的多项式回归
多特征可以由单特征构造:由单特征的不同项式进行生成多特征。
迭代收敛
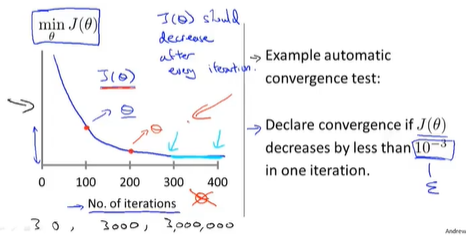
观察迭代过程是否收敛有两种方法:
- 自动收敛测试,看最终的代价函数值是否小于一个$\epsilon$。
- 收敛曲线(直观):损失函数值随迭代次数的变化曲线。
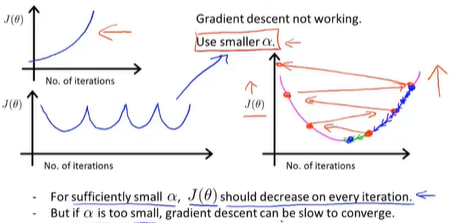
- 学习率过小,迭代速度慢
- 学习率过大,发散
- 选择学习率,倍数更迭(…,0.001,[0.003],0.01,[0.03],0.1,[0.3],1,…)[]中倍率为3x
求解模型参数
求解参数$\theta$的方法有:
- 梯度下降法:一步步迭代
- 正规方程法:提供求解参数最优解的方法
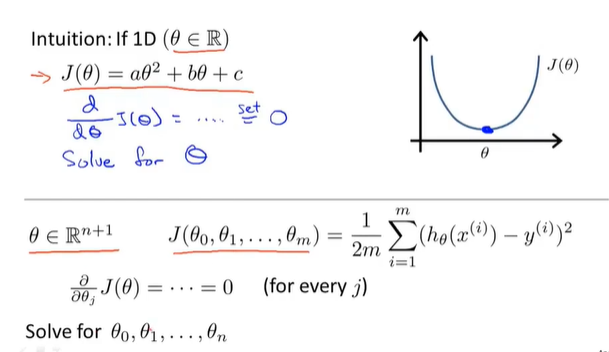
正规方程法
$$
\begin{aligned}
J(\theta)&=\frac{1}{2m}\sum_{i=1}^{n}(\theta^T x^{(i)})-y^{(i)})^2\
&=\frac{1}{2m}(\theta^T X-y)^T(\theta^T X-y)\
&=\frac{1}{2m}(X\theta-y)^T(X\theta-y)\ \tag{4-4}
&=\frac{1}{2m}(\theta^TX^T-y^T)(X\theta-y)\
&=\frac{1}{2m}(\theta^TX^TX\theta-y^TX\theta-\theta^TX^Ty+y^Ty)
\end{aligned}
$$
$$
\frac{\partial{J(\theta)}}{\partial\theta}=\frac{1}{2m}(2X^TX\theta-X^TY-X^TY+0) \tag{4-5}
$$
由$\frac{\partial{J(\theta)}}{\partial\theta}=0$得正规方程公式
$$\theta=(X^TX)^{-1}X^Ty \tag{4-6}$$
推导参考:正规方程求解特征参数的推导过程
正规方程可以不需归一化便可优良求解。
梯度下降法 vs 正规方程法
m training examples, n features.
- 梯度下降法
- 需要选择学习率$\alpha$
- 需要迭代次数多
- 当n过大时(10^6)时,仍然工作较好
- 正规方程法
- 不需选择$\alpha$
- 不许迭代,一步到位
- 需要计算$(X^TX)^{-1}$
- 在n非常大时,运算速度慢
在分类等问题中,正规方程法不适用,梯度下降法是更普适的方法。
在使用正规方程法时,若$(X^TX)$不可逆时,可以使用伪逆矩阵进行替代$(X^TX)^{-1}$。Matlab中pinv()计算伪逆矩阵,inv()计算逆矩阵。
正规方程法的进一步思考
$(X^TX)$不可逆的原因有:
- 包含了多余的特征,特征重复。
- 训练样本比要求解的特征参数多,欠拟合。
- Sol:删除部分特征,用正则化
归一化
让各个数值特征放缩在相同尺度,这样梯度下降法效果更好,更快收敛。
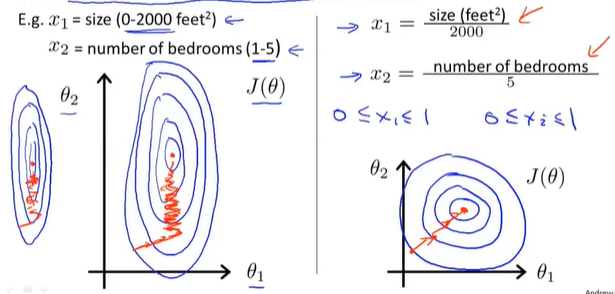
让特征数据在标准范围[-1,1]的范围内。若是与标准范围相差不大则不需要进行归一;变量范围与标准范围相差过大,则需要进行归一化,
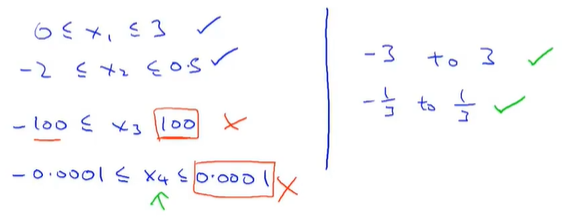
均值归一化
归一化后,数据的均值为0,最大值与最小值之差=1。
参考
- 吴恩达-机器学习-ch4
- 正规方程的推导-CSDN