
目标检测的评价指标:
- 精度评价 mAP(mean Average Precision):即各类别AP的平均值
- 速度指标
- (1)检测器每秒能处理图片的张数 FPS:在同一硬件条件下,每秒处理的图片数量或者处理每张图片所需的时间
- (2)检测器处理每张图片的时间
- 相当于$x=v \times t$
精度评价
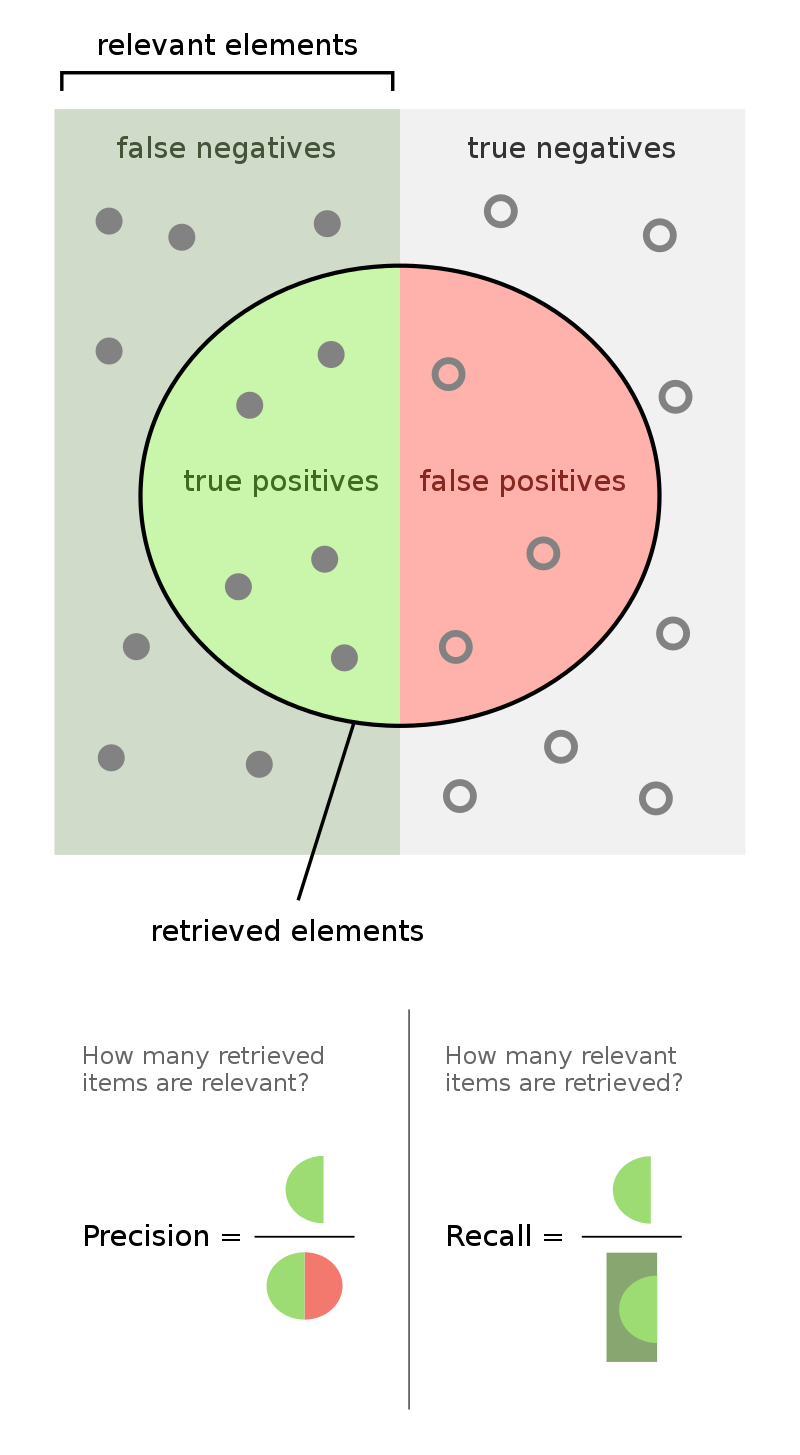
Recall和Precision
Recall和Precision是二分类问题中常用的评价指标,通常以关注的类为正类,其他类为负类,分类器的结果在测试数据上有4种情况:
1 | 实 际 |
注记:TP真阳性,FP假阳性,NP假阴性,TN真阴性。
真阳即预测为阳,实际为阳,假阳即预测为阳,实际为阴,假阴即预测为阴,实际为阳,真阴即预测为阴,实际为阴。
Recall度量的是「查全率」,Precision度量的是「查准率」。Recall和Precision的计算公式如下:
在预测为正中实际为正的概率 「查准率」
$$Precision=\frac{TP}{TP+FP}$$在实际为正中预测为正的概率 「查全率」
$$Recall=\frac{TP}{TP+FN}$$
预测准确度
$$accuracy=\frac{TP+TN}{TP+TN+FP+FN}$$
mAP(mean Average Precision)
对于一个搜索系统,相关条目在结果中的顺序是非常影响用户体验的,我们希望相关的结果越靠前越好。单一的precision不足以衡量系统的好坏,于是引入了AP(Average Precision)——不同召回率上的平均precision。
在信息检索当中,搜索一个条目,相关的条目在数据库中一共有5条,但搜索的结果一共有10条(包含4条相关条目)。这时precision=4/10,recall=4/5。4个条目出现在位置查询一(1,2,4,7)就比在查询二(3,5,6,8)效果要好,但两者的precision是相等的。
查询一:
| rank | correct | P | R |
|---|---|---|---|
| 1 | right | 1/1 | 1/5 |
| 2 | right | 2/2 | 2/5 |
| 3 | wrong | 2/3 | 2/5 |
| 4 | right | 3/4 | 3/5 |
| 5 | wrong | 3/5 | 3/5 |
| 6 | wrong | 3/6 | 3/5 |
| 7 | right | 4/7 | 4/5 |
| 8 | wrong | 4/8 | 4/5 |
| 9 | wrong | 4/9 | 4/5 |
| 10 | wrong | 4/10 | 4/5 |
查询二:
| rank | correct | P | R |
|---|---|---|---|
| 1 | wrong | 0 | 0 |
| 2 | wrong | 0 | 0 |
| 3 | right | 1/3 | 1/5 |
| 4 | wrong | 1/4 | 1/5 |
| 5 | right | 2/5 | 2/5 |
| 6 | right | 3/6 | 3/5 |
| 7 | wrong | 3/7 | 3/5 |
| 8 | right | 4/8 | 4/5 |
| 9 | wrong | 4/9 | 4/5 |
| 10 | wrong | 4/10 | 4/5 |
AP(查询一) = (1+1+3/4+4/7+0)/5 = 0.664
AP(查询二) = (1/3+2/5+3/6+4/8+0)/5 = 0.347
这个时候mAP = (0.664+0.347)/2 = 0.51
注:在计算AP的时候,precision取各个recall值下最大的那个,因为同一recall下最大的precision表示相关条目最先出现的位置。
目标检测的mAP
目标检测任务中,应该怎样衡量模型的性能?
其中一个标准就是信息检索那样,不仅要衡量检测出正确目标的数量,还应该评价模型是否能以较高的precision检测出目标。也就是在某个类别下的检测,在检测出正确目标之前,是不是出现了很多判断失误。AP越高,说明检测失误越少。对于所有类别的AP求平均就得到mAP了。
计算方法
mAP: mean Average Precision, 即各类别AP的平均值
TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次,GT认为是某处目标)
FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
FN: 没有检测到的GT的数量
PR曲线: Precision-Recall曲线
要计算mAP必须先绘出各类别PR曲线,计算出AP。如何采样PR曲线,VOC采用过两种不同方法。
- 在VOC2010以前,只需要选取当Recall >= 0, 0.1, 0.2, …, 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。
- 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取>=Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。
举例
对于Aeroplane类别,我们有以下输出(BB表示Bounding Box序号,IOU>0.5时GT=1):
| BB | confidence | GT |
|---|---|---|
| BB1 | 0.9 | 1 |
| BB2 | 0.9 | 1 |
| BB1 | 0.8 | 1 |
| BB3 | 0.7 | 0 |
| BB4 | 0.7 | 0 |
| BB5 | 0.7 | 1 |
| BB6 | 0.7 | 0 |
| BB7 | 0.7 | 0 |
| BB8 | 0.7 | 1 |
| BB9 | 0.7 | 1 |
因此,我们有 TP=5 (BB1, BB2, BB5, BB8, BB9), FP=5 (重复检测到的BB1也算FP)。除了表里检测到的5个GT以外,我们还有2个GT没被检测到,因此: FN = 2. 这时我们就可以按照Confidence的顺序给出各处的PR值,如下:
| Rank | Precision vs Recall |
|---|---|
| rank=1 | precision=1.00 and recall=0.14 |
| rank=2 | precision=1.00 and recall=0.29 |
| rank=3 | precision=0.66 and recall=0.29 |
| rank=4 | precision=0.50 and recall=0.29 |
| rank=5 | precision=0.40 and recall=0.29 |
| rank=6 | precision=0.50 and recall=0.43 |
| rank=7 | precision=0.43 and recall=0.43 |
| rank=8 | precision=0.38 and recall=0.43 |
| rank=9 | precision=0.44 and recall=0.57 |
| rank=10 | precision=0.50 and recall=0.71 |
- 07年的方法:我们选取Recall >={ 0, 0.1, …, 1}的11处Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0, 0。AP = 5.5 / 11 = 0.5
- VOC2010及以后的方法,对于Recall >= {0, 0.14, 0.29, 0.43, 0.57, 0.71, 1},我们选取此时Percision的最大值:1, 1, 1, 0.5, 0.5, 0.5, 0。计算recall/precision下的面积:AP = (0.14-0)x1 + (0.29-0.14)x1 + (0.43-0.29)x0.5 + (0.57-0.43)x0.5 + (0.71-0.57)x0.5 + (1-0.71)x0 = 0.5
计算出每个类别的AP以后,对于所有类别的AP取均值就得到mAP了
关于阈值Iou选取,与mAP的进一步思考
threshold到底是怎么影响precision和recall的呢?
用鸭子的例子,如果threshold太高, prediction非常严格, 所以我们认为是鸭子的基本都是鸭子,precision就高了;但也因为筛选太严格, 我们也放过了一些score比较低的鸭子, 所以recall就低了;
如果threshold太低, 什么都会被当成鸭子, precision就会很低, recall就会很高
这样我们就明确了threshold确实对鸭子的precision和recall产生影响和变化的趋势, 也就带来了思考, precision不是一个绝对的东西,而是相对threshold而改变的东西, recall同理,那么单个用precision来作为标准判断,就不合适。
这是一场precision与recall之间的trade off, 用一组固定值表述不够全面, 因为我们根据不同的threshold, 可以取到不同(也可能相同)的precision recall值。 这样想的话对于每个threshold,我们都有(precision, recall)的pair, 也就有了precision和recall之间的curve关系。
有了这么一条precision-recall curve, 他衡量着两个有价值的判断标准, precision和recall的关系, 那么不如两个一起动态考虑, 就有了鸭子这个class的Average Precision, 即curve下的面积, 他可以充分的表示在这个model中, precision和recall的总体优劣。
最后, 我们计算每个class的Average Precision, 就得到了mean Average Precision
速度指标
速度指标必须在同一硬件上比较。
FLOPS vs FLOPs
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
同一硬件,最大FLOPS是相同的,但不同深度学习算法下,处理每张照片的FLOPs是不同的。同一硬件处理相同图片所需的FLOPs越小,相同时间内,就能处理更多的图片,速度也就越快。
处理每张图片所需的FLOPs与许多因素有关,比如网络层数,参数量,选用的激活函数等等,这里仅谈一下网络的参数量对其的影响,一般来说参数量越低的网络,FLOPs会越小,保存模型所需的内存小,对硬件内存要求比较低,因此比较对嵌入式端较友好。
我们要的是衡量模型的复杂度的指标,所以选择FLOPs。
FLOPs计算
针对卷积层、池化层、全连接层有公式,可见目标检测的性能评价指标。
此处还有一个计算的开源在Pytorch框架中使用的FLOPs和参数量计算的小工具OpCouter,链接Lyken17/pytorch-OpCounter